

Machine Learning Pipeline Architecture

Hi, I'm Olanrewaju Alaba👋,
A passionate and results-driven software engineer with a knack for problem-solving and a love for creating efficient and scalable solutions with the latest industry trends and technologies.
A technical writer passionate about transforming complex concepts into clear, user-friendly documentation, I bring a wealth of experience in creating content that bridges the gap between technology and end-users.
Introduction.
In this article, a lot will be shared in the context and regards to machine learning pipeline architecture.
In our world, today, with how data is important and accessible, training a machine-learning model is highly possible. The presence of machine learning cannot be undermined especially in the field of automation, detection, prediction and technological assistance.
The creation and application of machine learning and models vary depending on the need and intended solutions. A view to machine learning (Models on Production) i.e(models on production environment) is administered through a certain infrastructure, Machine Learning Pipelines which we are going to explore today.
What is Machine Learning?
Machine learning is a subdivision/ subset of data science, a field of knowledge studying the extraction of value and meaningful insight from data. Meanwhile, machine learning suggests techniques and systems that train algorithms and programs on data to solve problems and make decisions with no or minimal rules, programming patterns and human intervention.
What is a Machine Learning Pipeline?
A machine learning pipeline is a technical infrastructure used to administer and automate machine learning processes and workflow, formatting raw data to intended output and valuable information.
Benefits of Machine Learning Pipeline Architecture.
Here are some of the benefits of machine learning pipeline architecture:
Flexibility
It is possible to make over workflows without changing the rest and other parts of the system (computation units and components) for better implementation.
Extensibility
It is easy and intuitive to create new functionalities, processes and components when the system is segregated into pieces.
Scalability
The availability of component/ computation segregation and separation provides the ability to scale if there is an issue. Each part of the computation is presented through a standard interface.
Bugs Prevention
Automated pipelines can prevent bugs. Manual machine learning workflow bugs might be really difficult to debug since inference of the model is still possible, but simply incorrect. With automated workflows, these errors can be prevented.
Less Cost
It reduces the expenditure and costs of data science projects and products.
Less Consumption of Time
It frees up development time for data scientists and increases their job satisfaction and experience. This improves efficiency and reduces the time spent getting set up on a new project and processes to update existing models.
Why does Machine Learning Pipeline Architecture Matter?
As algorithms start and begin to aid and enable machines to learn through data, it tends to be beneficial to both individuals and organisations in various aspects.
Below are a few reasons why machine learning pipeline architecture matter:
Timely Analysis And Assessment
It helps to understand and come up with strategic options and alternatives by analysing and assessing real-time data of the same or related environment.
Real-Time Predictions
Machine learning algorithms have been so beneficial to businesses by the provision of real-time predictions which tends to be closely accurate if not aiding in decisions making, implementation/ administration etc.
Transformation of Industries
Machine learning has led to the transformation of industries with its ability and expertise to provide valuable insights in Real-Time environments and situations.
Adoption and When to Use Machine Learning Pipeline Architecture.
There are a lot of advantages provided by the machine learning pipeline but it is not to be used in every data science product or project, it depends on the intended purpose and how vast it is.
However, situations or circumstances whereby continuous updating of models requires fine-tuning, e.g.(models with real-time data, especially users or been used in software or an application).
Pipelines have also become very much essential as machine learning projects and products grow. If the dataset or resource requirements are large, it allows for easy infrastructure scaling. If repeatability is important, this is provided through the automation and the audit trail of machine learning pipelines.
Adoption of Machine Learning Pipeline.
As aforementioned, industries, companies and products/ projects with massive amounts of data tend to use the machine learning pipeline as it helps in the fast, easy and efficient implementation of tasks.
Here are a few industries that have adopted the technologies of the machine learning pipeline:
Financial services
Businesses and financial industries and companies use machine learning technology to discover important insights into raw data and information. It is also used to prevent cyber attacks and fraudulent activities through detection, alert and cyber surveillance.
Government
Collecting/creating, processing, storage, transmission and control of national data is a huge task and especially protection and public safety are of importance. Machine learning also helps in the efficiency of the various sector by mining multiple data sources for insights.
Healthcare
In the healthcare field, machine learning technologies have helped in the analysation of data and information to diagnose medical illnesses and improve scientific treatment patterns.
Mining Industry
Machine learning technologies have helped the mining industry by sourcing and analyzing resources (energy sources, minerals etc.). It has also made the process more efficient, cost-effective and less time-consuming.
Machine Learning Pipeline Architecture and Stages.
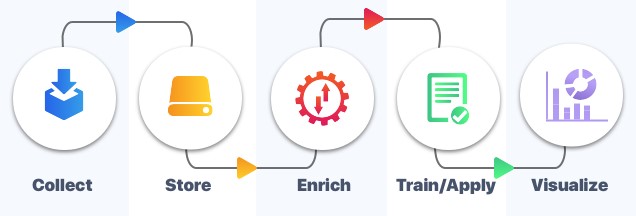
A machine learning pipeline comprises several stages. Data is processed in all stages for the cycle to run, and it is transmitted from one stage to the other. i.e., the output of a processing unit supplied as an input to the next step. There are different stages but we are checking out the four main and major stages Pre-processing, Learning, Evaluation, and Prediction.
Pre-processing
Data processing is a process of basic transformation of data. Transforming raw data collected from users into an understandable and consumable format for the model. The outcome product of data pre-processing is the final dataset used for training the model and testing purposes.
Learning
This process involves the extraction of the pre-processing output result(model understandable format) for the appropriate application in a new setting or circumstances. The aim is to utilize a system for a specific input-output transformation task.
Evaluation
This involves assessing the performance of the model using the test subset of data to understand prediction accuracy. The predictive implementation of a model is evaluated by comparing predictions on the evaluation dataset with true values using a variety of metrics.
Prediction
The model's performance to determine the outcomes of the test data set was not used for any training or cross-validation activities. The best model on the evaluation subset is selected to make predictions on future/new instances.
Machine Learning Pipeline Infrastructure/ Model Preparation Process.
Machine learning Infrastructure consists of the resources, processes, and tooling essential to the operation, training, development and deployment of machine learning models. Every stage of its workflow is supported by machine learning infrastructure and is the base of its model. There is no specific infrastructure because it depends on the model available in a product or project.
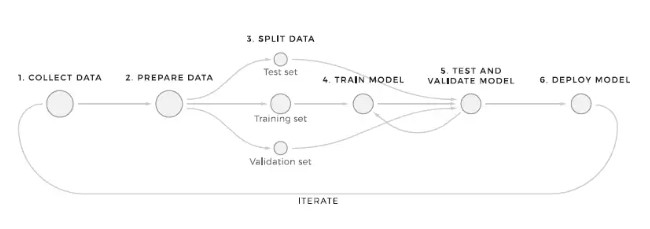
Here are some of the major components of machine learning pipeline architecture:
Model Selection
Model selection refers to the process of choosing the model that best generalizes for a specific task or different data. It includes accuracy, interpretability, complexity, training time, scalability, and trade-offs.
Data Ingestion
This refers to the process of extracting and transferring large data in an automated way from multiple sources.
Model Testing
Model testing refers to the process where the performance of a fully trained model is evaluated on a testing set. It involves explicit checks for behaviours that are expected of the model.
Model Training
It is the process of feeding a machine learning algorithm with data to help identify and learn good values for all attributes involved.
Visualisation and Monitoring
It refers to the process of tracking and understanding the behaviour of a deployed model to analyze performance.
Machine Learning Inference
Machine learning inference is the process of running live data into a machine learning algorithm to calculate output such as a single numerical score.
Model Deployment
Model deployment is the process of implementing a fully functioning machine learning model into production where it can make predictions based on data.
Software/ Applications for Building Machine Learning Pipelines.
Azure Machine Learning Pipelines
Azure ML pipeline helps to build, manage, and optimize its workflows. It is an independently deployable workflow of a complete ML task.
Google ML Kit.
Deploying models in the mobile application(Andriod and IOS) via API, there is the ability to use the Firebase platform to leverage ML pipelines and close integration with the Google AI platform.
Amazon SageMaker
It builds, trains, and deploys machine learning models for any use case with fully managed infrastructure, tools, and workflows. One of the key features is that you can automate the process of feedback about model prediction via Amazon Augmented AI.
Kubeflow Pipelines
Kubeflow Pipelines is a platform for building and deploying portable, scalable machine learning (ML) workflows based on Docker containers.
TensorFlow
TensorFlow is a free, open-source and end-to-end(E23) platform software library for machine learning developed by Google. It makes it easy for you to build and deploy ML models.
Machine Learning Pipeline Tools.
Data Obtainment
Database: PostgreSQL, DynamoDB.
Distributed Storage: Apache Spark/Apache Flink.
Data Scrubbing / Cleaning
Scripting Language: SAS, Python, and R.
Processing in a Distributed manner: MapReduce/ Spark, Hadoop.
Data Wrangling Tools: R, Python Pandas.
Data Exploration / Visualization
Data Predictions
Machine Learning algorithms: Supervised, Unsupervised, Reinforcement, Semi-Supervised, and Semi-unsupervised learning.
Important libraries: Python (Scikit learn) / R (CARET).
Result Interpretation
Data Visualization Tools: ggplot, Seaborn, D3.JS, Matplotlib, Tableau.




